統計や機械学習で確率分布を扱う際には、モーメントという概念がしばしば登場します。
モーメント(積率) は、その確率分布の期待値や分散、歪度、尖度といった統計量を導出することができ、実用上非常に便利で重要な概念です。
しかし、モーメントの勉強をしていても、参考書等では数式が天下り的に提示されることも多く、なぜモーメントがこのような数式で表現されるのか一向に理解ができす、その結果として全く頭に入ってこない、、という人も多いと思います。
今回は、この確率統計の分野で非常に重要なモーメントについて、できるだけ分かりやすく解説をします。また、モーメントと積率母関数(モーメント母関数)との関係性についても解説していきます。
モーメント(積率)の定義
まず最初にモーメントの定義を導入します。ここでも天下り的になってしまいますが、定義を示した上で、解説をしていくといったスタイルで進めていきます。
モーメントの定義
ある確率変数$X$に対し、r次のモーメントを
\begin{equation}
\mu_r = E[X^r]
\end{equation}
と定義する。また、これを原点周りのr次のモーメントという。一方で、確率変数$X$の平均を$r$としたとき、
\begin{equation}
\mu_r = E[(X^r - \mu)]
\end{equation}
(2)で定義される統計量を、$r$次の平均周りのモーメントという。
モーメントと平均、分散、歪度、尖度の関係性
先ほど、モーメントの定義について解説しました。
なぜ統計学などの参考書で、モーメントについて導入されているかというと、モーメントを利用することで、確率分布の平均(期待値)や分散、歪度、尖度といった統計量を表現することができるからです。
例えば、確率分布の統計は次のように定義されます。
確率分布の平均(期待値)
\begin{equation}
\mu = E[X]
\end{equation}
ここまでは大丈夫でしょうか。期待値について怪しい人は、こちらでも解説しているので、参考にしてください。
[
確率変数の期待値について徹底解説
確率変数の期待値は、機械学習の学習をする中で、非常によく登場する概念です。確率変…](https://disassemble-channel.com/expected-value-random-variable/)
(3)式と(1)式を比較してみると、確率分布の期待値というのは、1次のモーメントということがわかります。続いて、同様に、分散、歪度、尖度も見ていきましょう。
確率分布の分散、歪度、尖度
確率分布の分散
\begin{equation}
Var[X] = E[(X- \mu)^2]
\end{equation}
確率分布の歪度(skewness)
\begin{equation}
skewness[X] = \frac{E[(X- \mu)^3]}{\sigma^3}
\end{equation}
確率分布の尖度(kurtosis)
\begin{equation}
kurtosis[X] = \frac{E[(X- \mu)^4]}{\sigma^4}
\end{equation}
確率分布の分散、歪度、尖度はこのように定義されています。これらの定義とモーメントの式を見比べてみると、これらの定義全てにモーメントが利用されていることがわかります。
(4)の分散の定義では、これは2次の平均周りのモーメントになっています。歪度においては、平均周りの3次のモーメントを、その確率分布の$\sigma$(標準偏差)の3乗で割った値になっています。尖度においてもほぼ同様に、平均周りの4次のモーメントを、$\sigma$の4乗で割った値となっています。
なぜモーメントやモーメント母関数は重要なのか
平均や分散、歪度や鮮度は、その確率分布を特徴づける重要な量ですが、これらの重要な量はモーメントを用いることで、記載できることがわかりました。それゆえに、モーメントは重要なのです。
しかし、モーメントが重要なのはこれらだけではありません。実は後で説明するモーメント母関数を利用することで、これらの$r$次のモーメントを簡単に導出することができるので、実はここまで重要な概念となっているのです。
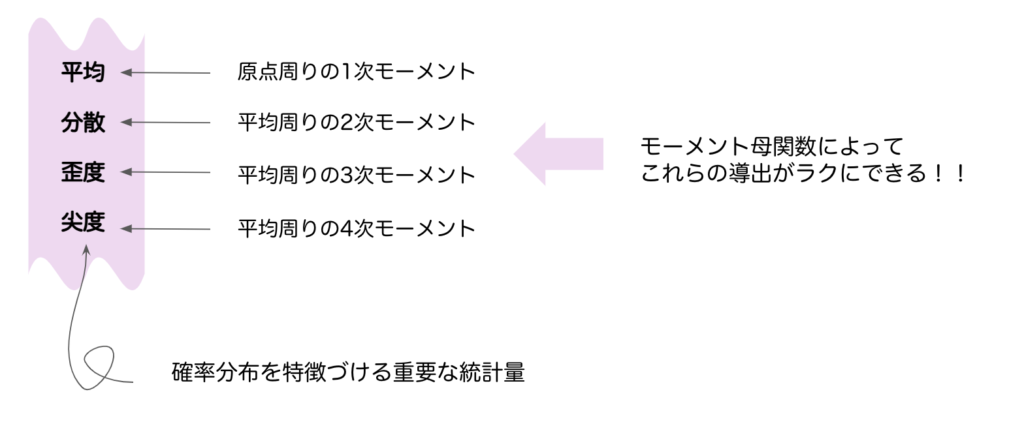
イメージとしてはこのようになります。この時点ではモーメント母関数を用いれば、いろいろ便利なんだなあーくらいの認識で大丈夫です。
モーメント母関数
それではモーメント母関数はどのようなものでしょうか。モーメントの時と同様に、まずは定義を示します。
モーメント母関数(積率母関数)の定義
ある確率変数$X$において、任意の実数$t$を用いてモーメント母関数$M_t$は次のように定義される。
\begin{equation}
M_t(X) = E[e^{tX}]
\end{equation}
モーメント母関数の定義はこのようになっています。
(7)式は期待値の計算になっています。ある確率変数$X$における$e^{tX}$の期待値がモーメント母関数ということです。この辺りは期待値の定義が怪しい人は理解が難しいと思うので、こちらの記事も参考にしてください。
[
確率変数の期待値について徹底解説
確率変数の期待値は、機械学習の学習をする中で、非常によく登場する概念です。確率変…](https://disassemble-channel.com/expected-value-random-variable/)
(7)の式は実際に計算するときは、次のようになります。
連続確率変数のモーメント母関数
\begin{equation}
M_t(X) = \int_{-\infin}^{\infin} e^{tx} p(x)dx
\end{equation}
離散確率変数のモーメント母関数
\begin{equation}
M_t(X) = \sum_{x} e^{tx} p(x)
\end{equation}
これがモーメント母関数の計算式です。
モーメント母関数を利用することで、平均や分散、歪度や尖度などに用いられる$r$次のモーメントがすぐに求められると言いましたが、それはどういうことか説明したいと思います。
モーメント母関数(積率母関数)が便利な理由
モーメント母関数を利用すると、$r$次のモーメントを簡単に求めることができます。モーメント母関数は、確率変数$X$に対して、$e^{tX}$の期待値を取るこで得ることができます。
ここで、$e^{tX}$をマクローリン展開すると次にようになります。
\begin{equation}
e^{tX} = 1 + tX + \frac{t^2X^2}{2!} + \frac{t^3X^3}{3!} + \dots...
\end{equation}
このマクローリン展開した$e^{tX}$に対して、期待値を取る、つまりモーメント母関数を求めると、
\begin{equation}
\begin{split}
M_{X}(t)
&= E[e^{tX}] \\
&= E[1 + tX + \frac{t^2X^2}{2!} + \frac{t^3X^3}{3!} + \dots ] \\
&= E[1] + tE[X] + \frac{t^2}{2!}E[X^2] + \frac{t^3}{3!}E[X^3] + \dots
\end{split}
\end{equation}
となります。ここで、(11)式で表現できるモーメント母関数を$t$で1回微分すると、
\begin{equation}
\begin{split}
M'_{X}(t) &= E[X] + tE[X^2] + \frac{t^2}{2}E[X^3] + \frac{t^3}{3}E[X^4] + \dots
\end{split}
\end{equation}
ここで、(12)式に$t=0$を代入すると、
\begin{equation}
\begin{split}
M'_{X}(0) = E[X]
\end{split}
\end{equation}
となります。
また、(11)式を2階微分、つまり(12)式をさらに$t$で微分して、$t=0$を代入すると、
\begin{equation}
\begin{split}
M''_{X}(0) = E[X^2]
\end{split}
\end{equation}
となります。
つまり、積率母関数を$r$階微分することで、その確率分布の$r$次の平均周りのモーメントを簡単に求めることができます。